什么是 CUDA
CUDA 的全称是 Compute Unified Device Architecture,即计算统一设备架构,统一了 GPU 内部的顶点与像素处理单元,使其成为通用的并行计算核心,从而让 GPU 具备了通用计算能力。根据英伟达的官方文档介绍:CUDA 是由英伟达开发的并行计算平台和编程模型。还是很迷茫,通过 CUDA 官方文档的解读、各路技术博客的拜读,最终了解了 CUDA 已经并非是一个架构,而是一套复杂到我没有语言描述的“一坨”东西。但结合上下文语境可以了解文章中某处的 CUDA 为何意。
在解读 CUDA 之前,先聊一下我对英伟达软件栈的认识。
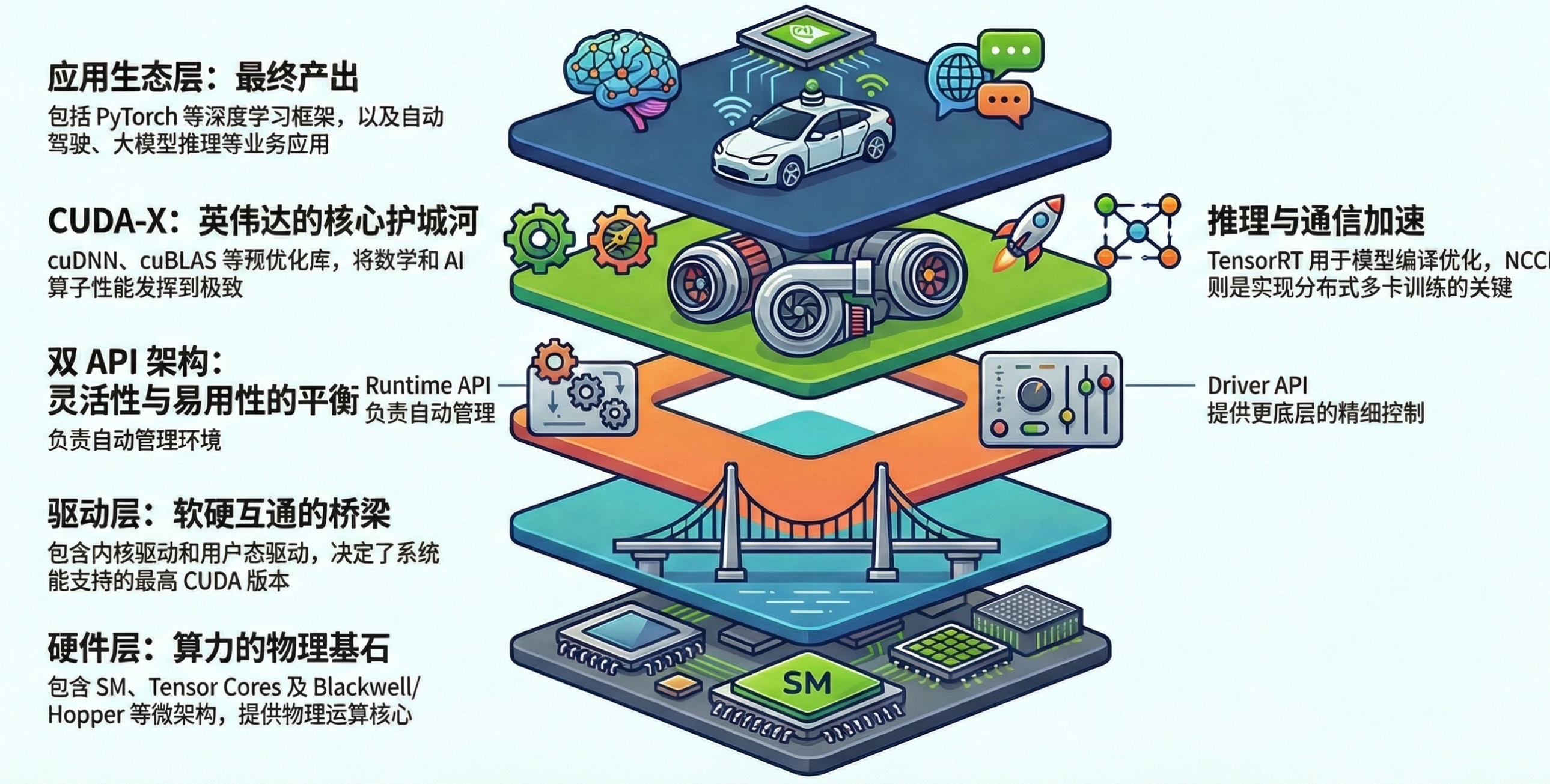
英伟达的硬件层(如 CUDA Cores 和 Tensor Cores)提供了极致的算力物理基石。虽然硬件设计极其复杂,但通过分层架构,普通开发者无需直接处理物理电路。
连接软件与硬件的桥梁是驱动层,它包含运行在操作系统核心的 KMD(内核态驱动) 和运行在用户空间的 UMD(用户态驱动)。
在驱动之上,英伟达提供了双 API 架构:
- Driver API:提供更底层的精细控制;
- Runtime API:基于驱动层封装,通过自动管理环境提升了易用性。
基于这些 API,英伟达构建了其核心护城河——CUDA-X 加速库(如 cuDNN、TensorRT)。正是这些高度优化的函数库,支撑起了顶层的 PyTorch 等深度学习框架及各种 AI 应用,构成了最终的应用生态层。
接下来分析一些具体语境中 CUDA 为何?
1. 常见描述 1
英伟达的 CUDA 生态护城河
这是各大媒体报道中常提到的,我的个人理解,这就是上述一大坨东西,只可意会不可言传的东西。
2. 常见描述 2
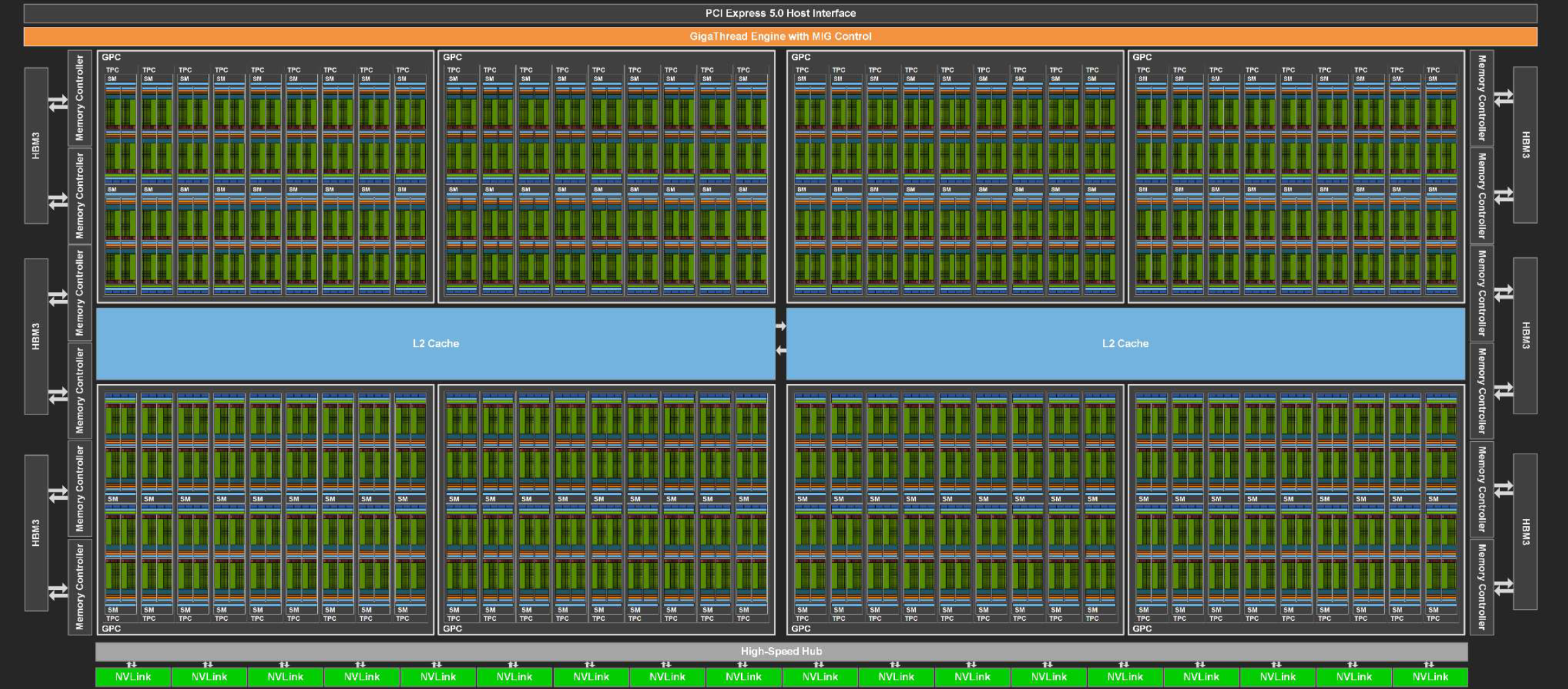
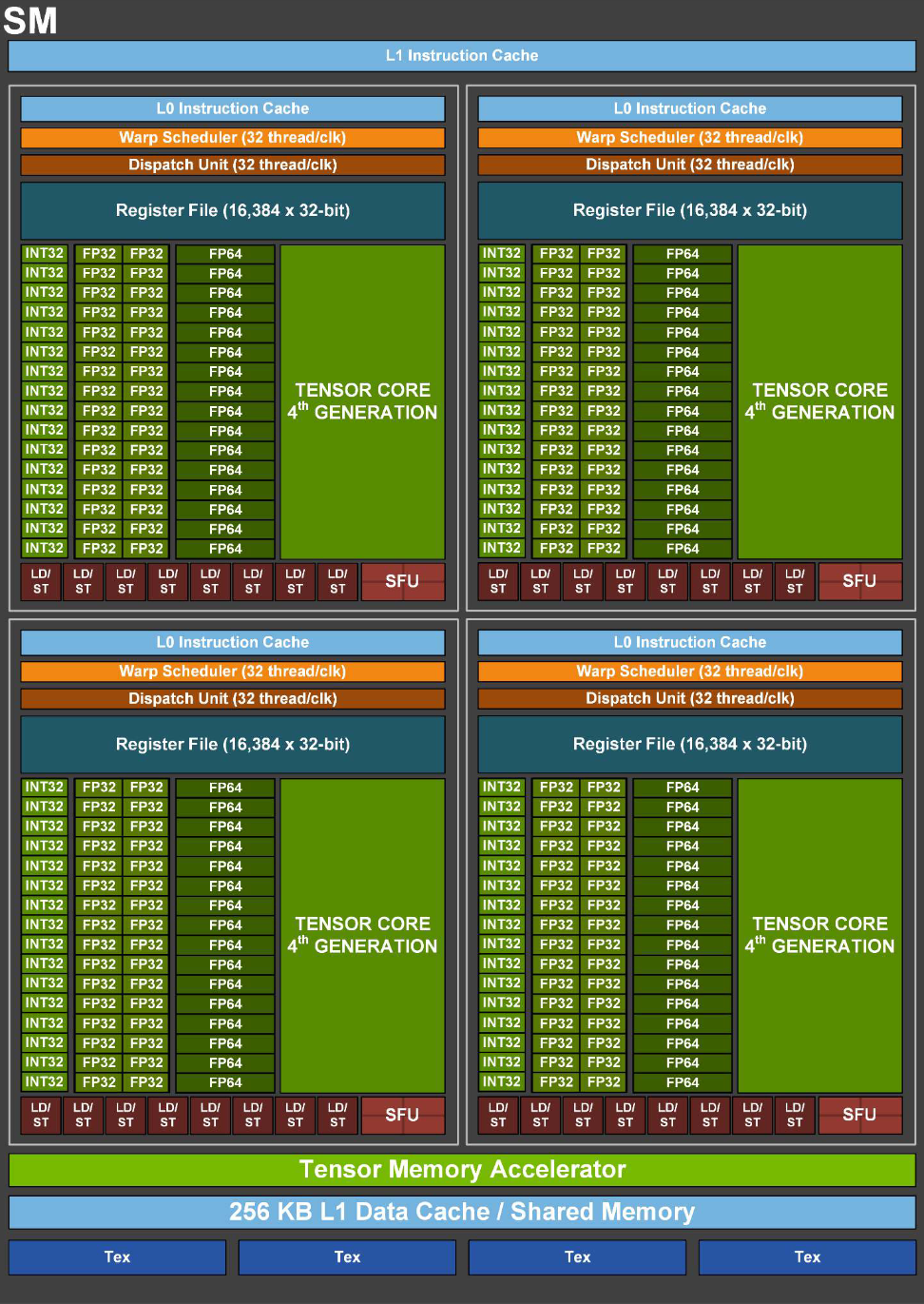
CUDA 核心
这是在描述英伟达的硬件时提到的,CUDA Cores,它们的作用是并行的完成各种计算。称为 CUDA Core 是在最初 CUDA 提出时,这是当时的英伟达 GPU 的计算核心。现在,为了适应 AI 的大规模矩阵,英伟达的各种 GPU 都加上了 Tensor Cores 来进行高速矩阵乘法运算。
3. 常见描述 3
写 CUDA 算子(以 C++ 为例)
这是算子开发工程师常提到的,它们的使命是处理最底层的并行计算细节与显存管理,封装成高性能的算子。这样,上层的算法工程师(如使用 PyTorch 的人)才能专注于模型逻辑,而无需关心硬件层面的复杂性。
这里的 CUDA 我理解为 CUDA 编程模型 + CUDA C++ 语言扩展,基于 CUDA 编程模型了解软件层面的硬件,然后用 CUDA C++ 语言扩展编写算子,即 CUDA 算子。
4. 常见描述 4
安装 CUDA
这是在配环境时常说的,这里通常表示为以下两种
- 英伟达的显卡驱动:这是英伟达的内核态驱动和用户态驱动,随驱动安装的有 nvidia-smi 这个工具,它可以查看安装的驱动的版本,也是一个常见的查看 GPU 集群中显卡是否被使用的工具。
- 英伟达的显卡软件工具集:它不包含驱动(虽然安装包里可选带驱动),主要包含 nvcc 编译器(用于编译 .cu 代码)、开发头文件(如 cuda_runtime.h)、NSight 性能分析工具、以及 cuBLAS/cuFFT 等库。