GPU 是如何执行的
文章大纲
1. Kernel 是什么?
点击后可快速跳到对应章节
在高性能计算(HPC)和深度学习领域,当我们调用 Nvidia GPU 时,表面上使用的是 C++ 或 Python 这样的高级语言,但真正驱动硅片运行的灵魂却是 CUDA kernel。那么,这些优雅的高级代码究竟经历了怎样的‘奇幻漂流’——经过编译、转换与调度,最终化作 GPU 核心上奔流的电信号?
1. Kernel 是什么?
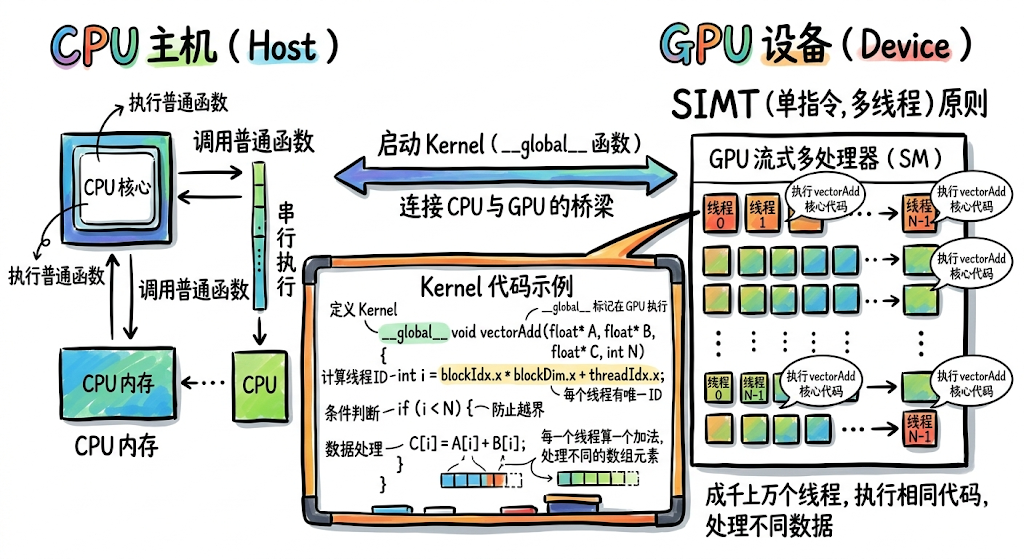
要理解 GPU 的算力奥秘,我们首先要回答一个基础问题,即 kernel 是什么?
在 GPGPU(通用图形处理器)编程中,kernel(内核)是连接 CPU(Host)与 GPU(Device)的桥梁。
从本质上讲,kernel 是一个函数。但它与普通的 CPU 函数有两个关键区别:
- 运行位置:它在 GPU 设备上执行。
- 执行方式:它遵循 SIMT(Single Instruction, Multiple Threads) 原则。
当你从 CPU 调用一个 kernel 时,你实际上并不是在“调用一个函数”,而是在命令 GPU:“启动成千上万个线程,所有线程都执行这一段相同的代码,但每个线程处理不同的数据。”
1.1 代码示例(CUDA kernel)
// 这就是一个 kernel,用 __global__ 关键字标记
__global__ void vectorAdd(float* A, float* B, float* C, int N) {
// 1. 计算当前线程的 id
int i = blockIdx.x blockDim.x + threadIdx.x;
// 2. 每一个线程算一个加法
if(i < N) {
C[i] = A[i] + B[i];
}
}
2. Kernel 代码的编译:从意图到指令
写好的 C++/CUDA 代码,并不是直接喂给 GPU 吃的。它需要经历一个从“人类意图”到“机器动作”的残酷翻译过程。这个过程通常由 NVCC 编译器完成,它决定了代码的理论性能上限。
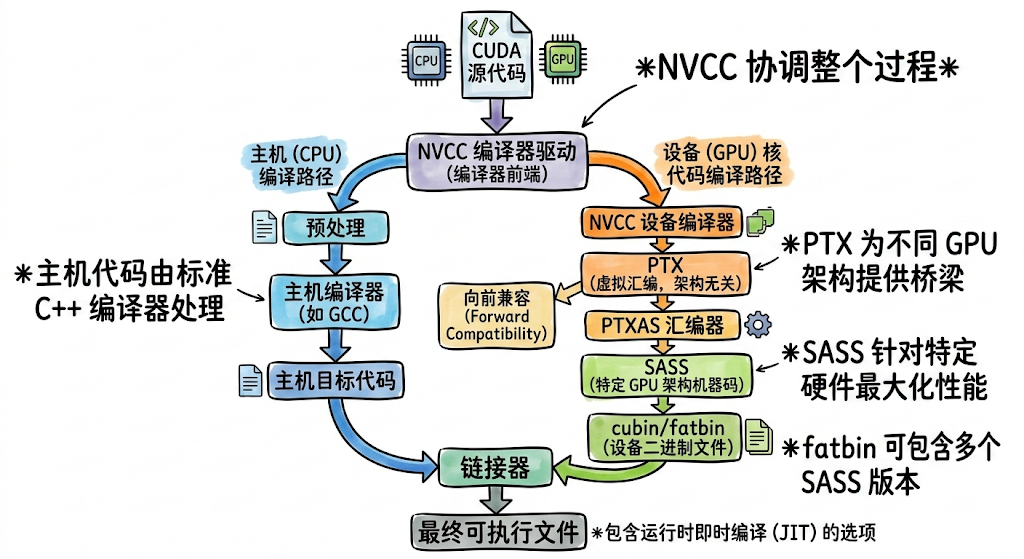
2.1 第一阶段:前端编译(Frontend)——生成 PTX
编译器首先将 kernel 代码与 CPU 代码分离。Kernel 代码被翻译成 PTX(Parallel Thread Execution)。
- PTX 是什么? 它是 GPU 的虚拟汇编语言(Virtual ISA)。
- 特点: 它是“理想化”的。
- 无限寄存器: PTX 假设 GPU 拥有无限数量的虚拟寄存器。
- 硬件无关: 它只描述逻辑意图(例如:“把 A 加到 B 上”),不关心你的显卡是 5 年前的 GTX 1080 还是新的 H200。这保证了代码的兼容性。
2.2 第二阶段:后端编译(Backend)——生成 SASS
驱动程序或 ptxas 工具将 PTX 翻译成 SASS(Streaming Assembler)。
- SASS 是什么? 它是物理汇编语言,是真正的二进制机器码。
- 特点: 它是“现实”且“残酷”的。这一步必须面对物理限制:
- 寄存器分配(Register Allocation): 物理寄存器是有限的。编译器必须通过图着色算法,决定哪些变量放寄存器(快),哪些必须“溢出”到 Local Memory(慢)。
- 指令调度(Instruction Scheduling): 编译器知道每条指令的延迟(Latency)。
- 策略: 它会重排指令顺序,把耗时的内存读取指令(LDG)尽量提前,随后插入不依赖该数据的计算指令,用计算来填补读取内存的等待时间。
- 控制码插入(Control Codes): SASS 代码中包含硬件控制码,显式告诉 GPU:“执行完这条指令后,必须等待 10 个时钟周期再发射下一条”。这意味着 GPU 硬件不需要复杂的乱序执行电路,软件已经把路铺好了。
3. 从 kernel 被执行的角度:微观世界的生死时速
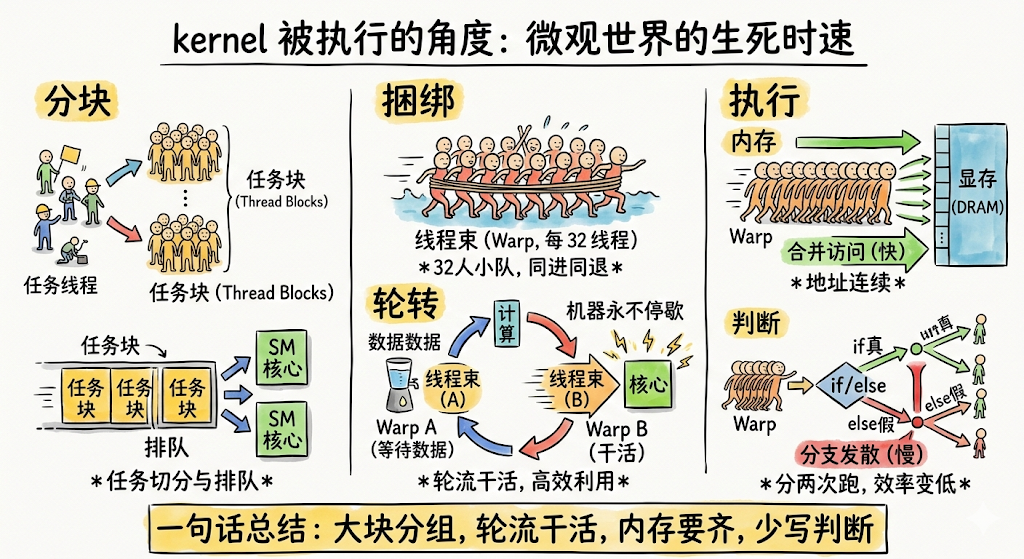
现在,SASS 代码已经准备好,数据也已经从 CPU 内存搬运到了 GPU 显存(H2D Copy)。CPU 发出了 Launch 命令。我们将视角缩小到微米级别,看看 GPU 的核心单元——流多处理器(SM) 内部发生了什么。
3.1 Step 1:派发与落地(The Launch)
GPU 的总指挥——GigaThread Engine 接管任务。它将你的任务切割成一个个 Thread Block(线程块)。
- 软硬映射: 软件上的 Block 会被分发给硬件上的 SM(Streaming Multiprocessor)。
- 驻留: 一旦 Block 进驻某个 SM,它就会一直待在那里直到执行结束。如果 SM 满了,剩下的 Block 就得排队。
3.2 Step 2:编队(Warp Formation)
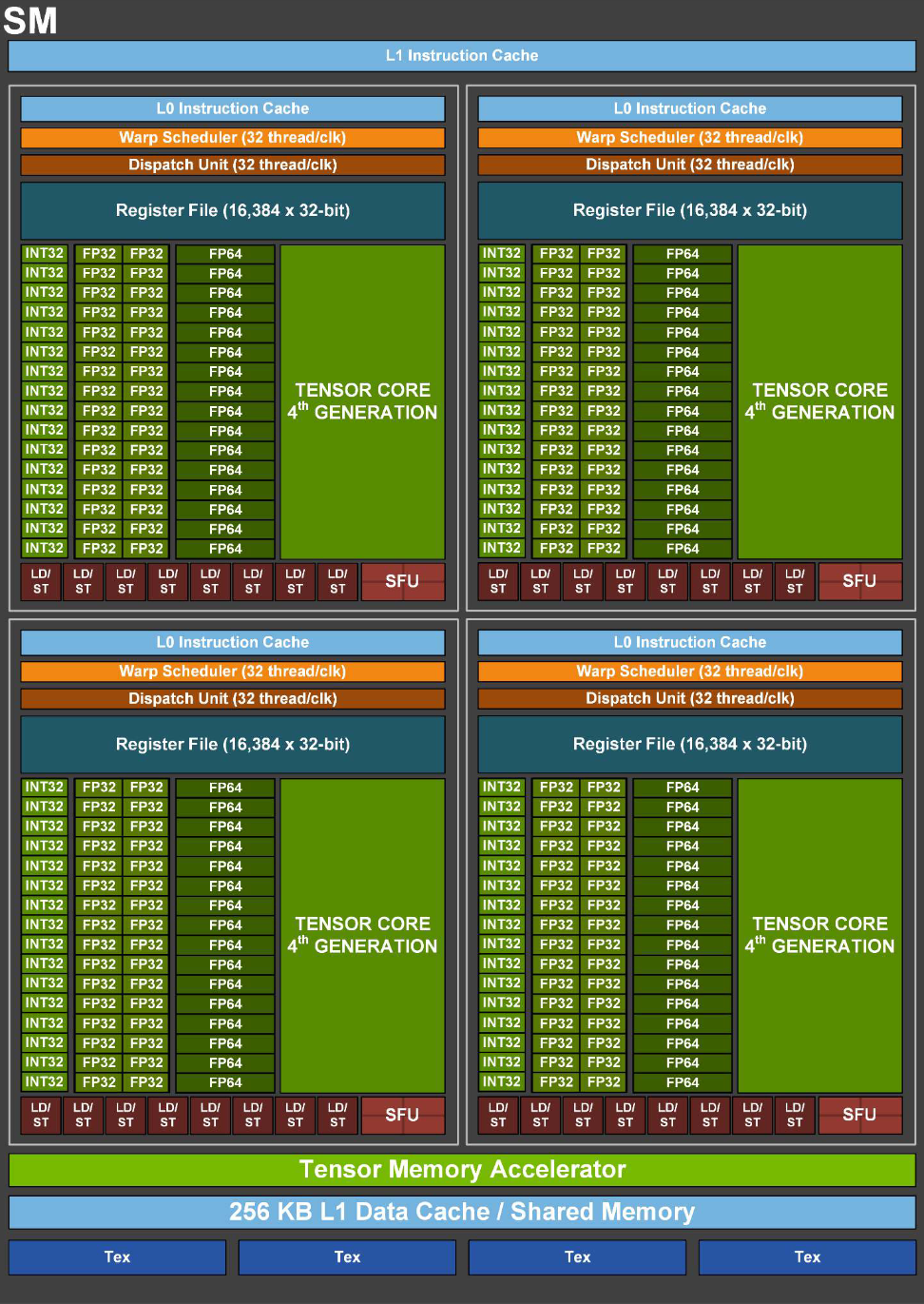
SM 内部并不是一个个调度线程的,那样太慢了。SM 内部的 Warp Manager 会将 Block 里的线程切分。
- Warp(束): 每 32 个线程 被捆绑成一组,称为一个 Warp。
- 共进退: 这 32 个线程是“同生共死”的,它们共用一个程序计数器(PC),在同一时刻执行同一条指令。
3.3 Step 3:调度循环(The Heartbeat)
SM 内部通常有 4 个 Warp Scheduler(调度器)。
- 筛选(Scan): 每个时钟周期,调度器扫描它负责的所有 Warp,看谁是 "Ready" 的?
- Ready 条件: 上一条指令执行完了,需要的操作数也都准备好了(没有在等内存数据)。
- 发射(Issue): 选中一个 Ready 的 Warp,将其指令发射到执行单元(CUDA Cores 或 LD/ST 单元)。
- 掩盖(Hiding): 如果 Warp A 卡在内存读取上(Stall),调度器会零开销地立刻切换到 Warp B。
- 结论: 只要你有足够多的 Warp,SM 的计算单元就永远不会闲着。这就是 GPU 吞吐量巨大的秘密。
3.4 Step 4:物理执行(Execution)
指令最终变成了电路的开关:
- 运算指令: 进入 ALU(INT32/FP32 Core),32 个线程的数据并行计算。
- 访存指令: 进入 Load/Store(LD/ST) 单元。
- 合并访问(Coalescing): 如果 32 个线程读取的地址是连续的,硬件会将它们合并成 1 个 显存事务,效率极高。
- 非合并访问: 如果地址是乱序的,可能会分裂成 32 个 事务,导致严重的内存带宽浪费。
- 分支发散(Divergence): 如果遇到
if(tid < 16):- 硬件生成掩码(Mask)。
- 先执行
if分支(前 16 个线程干活,后 16 个线程被掩码屏蔽,虽然不干活但也要陪跑)。 - 再执行
else分支(翻转掩码)。 - 最后重新汇合。这就是为什么 GPU 讨厌复杂的逻辑判断。
4. 软件视角:编程模型与性能哲学
如果我们把显微镜移开,回到软件架构师的视角,GPU 的硬件工作方式可以总结为一套独特的编程模型。理解这套模型,你就能理解为什么要那样写代码。
4.1 核心一:层级化的并行结构(Hierarchy)
为了适配硬件的扩展性,软件上强迫你将问题分解为三个层级:
- Grid(网格): 整个问题的全集。
- Block(块): 独立的子任务。
- 对应硬件: SM。
- 设计哲学: Block 之间是无法通信的。这保证了 GPU 的可扩展性——你的程序可以在只有 10 个 SM 的笔记本显卡上跑,也可以在有 144 个 SM 的 H100 上跑,硬件调度器可以随意安排 Block。
- Thread(线程): 最小的工作单位。
4.2 核心二:内存层级的博弈(Memory Hierarchy)
GPU 编程的本质是 “计算是廉价的,数据移动是昂贵的”。软件视角下,你拥有三种关键内存:
- Global Memory: 显存(VRAM)。容量巨大但极慢(几百个周期延迟)。
- Shared Memory: 片上内存。容量极小(每 Block 只有几十 KB)但极快。
- 它是可编程的 L1 缓存。
- Registers: 寄存器。最快,每线程私有。
优化模式: 优秀的 GPU 程序总是试图把数据从 Global Memory 搬运到 Shared Memory,在 Shared Memory 内部反复重用,最后再写回。
4.3 核心三:延迟隐藏(Latency Hiding)
这是 GPU 设计的终极哲学。
- CPU 的哲学:Minimizing Latency。利用巨大的缓存(L3 Cache)和复杂的分支预测,让单个任务跑得极快。
- GPU 的哲学:Hiding Latency。利用巨大的吞吐量(Throughput)。
工作原理:
-
你需要在软件中启动远超核心数量的线程(High Occupancy)。
-
当一组线程(Warp A)在等待漫长的内存读取(例如需要 400 个周期)时,硬件不应该等待,而是自动切换到另一组线程(Warp B)进行计算。
-
只要你的线程足够多,就能把昂贵的内存延迟完全“藏”在密集的计算时间背后。