Harness Engineering:把模型变成 agent 的那层系统
文章大纲
1. 什么是 Harness?
点击后可快速跳到对应章节
本文的核心就是:Agent = Harness + Model
过去的观点认为,Agent 能力的提升,主要靠 Model 智力的提升,但现在的普遍的观点是,Model 和 Harness 两者共同进化的结果。
1. 什么是 Harness?
Harness 不是模型本身,而是包在模型外面的那层运行系统。
裸模型只能根据输入生成输出,但真实任务往往要求它继续往前做事:读写文件、调用工具、执行代码、观察结果、根据反馈修正错误,并在边界内持续完成任务。这些都不是模型天然具备的能力,而是 harness 提供的。
所以可以简单理解为:
model负责“想”harness负责“让它能做”
一个 harness 通常包括这些部分:
- system prompt:定义模型的角色、目标、行为边界和工作方式
- tools / skills / mcp:让模型能够调用外部工具,而不只是输出一段文本
- 文件系统:给 agent 一个可读写的工作区,用来保存中间结果、操作代码和管理上下文
- bash / 代码执行环境:让模型能真正运行命令、执行脚本、安装依赖、调用程序
- sandbox / 权限控制:限制 agent 可以访问什么、修改什么、执行到什么程度
- 浏览器、日志、测试、截图等验证工具:让 agent 能观察执行结果,而不是只靠自己猜测
- 编排逻辑:比如 subagent、handoff、模型路由、重试机制、hook、循环控制
- memory、search、context compaction:帮助 agent 管理上下文,避免重要信息被淹没,也让任务可以跨轮次延续
因此,harness 不是单个组件,而是一整套让模型能够在真实环境中持续执行任务的外部系统。
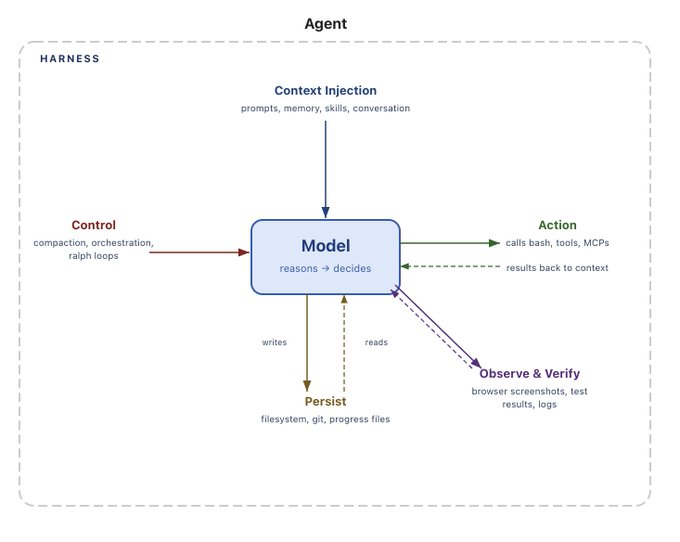
2. 什么是 Harness Engineering?
Harness engineering 不是简单给模型接几个工具,而是围绕“怎样让 agent 更可靠地完成任务”展开的系统设计。
它关心的是:
- 我们希望 agent 表现出什么行为
- 它最容易在哪里失败
- 需要补哪些外部能力
- 这些能力该如何组织、约束和暴露
- 怎样通过外部反馈验证设计是否有效
所以它的核心不是“加能力”,而是:从目标行为出发,识别失败模式,再反推所需的执行能力、约束机制和验证闭环。
如下图所示,agent 想要表现出的行为,并不是模型天然具备的,而是需要通过相应的 harness 能力来补齐。接下来这些模块,可以理解为这套方法在不同问题上的具体落地。
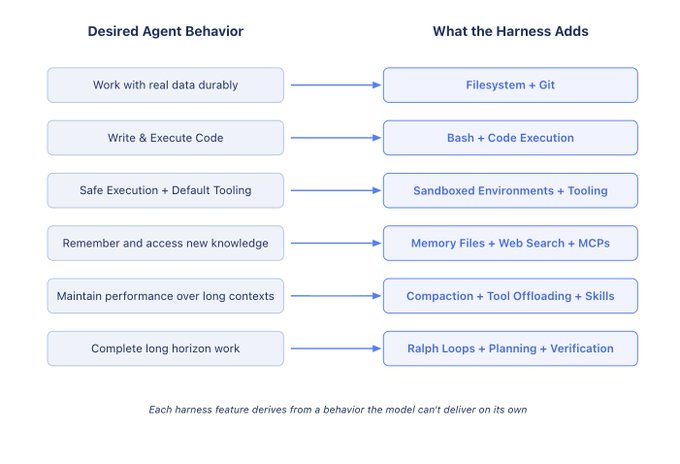
下面将逐个介绍上图中的一些 harness。
3. 持久地处理真实数据:Filesystem + Git
如果希望 agent 能真正处理现实任务,它就不能只依赖上下文窗口里的那一点信息。因为很多任务不是一次问答就能结束的,而是需要持续读取资料、保存中间结果、修改文件,并在后续步骤中继续使用这些结果。
这时候,文件系统就成为最基础的 harness 能力之一。它为 agent 提供了一个可读写的工作区,使其能够:
- 读取项目代码、配置和文档
- 保存中间结果、草稿和计划
- 在多轮任务中延续状态
- 与人类或其他 agent 共享产物
在代码、文档和配置类任务中,git 往往是文件系统之外的重要补充。它提供版本管理、差异查看、回滚和协作边界,让 agent 不只是“改文件”,还能明确知道自己改了什么、当前处于什么状态,以及如何安全撤回某一步操作。
换句话说,如果没有文件系统,agent 往往只能停留在“基于当前输入回答”;而在需要持续修改和迭代的任务里,git 又进一步增强了这种工作连续性。
4. 编写并执行代码:Bash + Code Execution
很多 agent 任务并不是靠“说”就能完成的,而是必须通过执行来推进。
比如你让一个编程 agent 修 bug,它不能只告诉你“我觉得这里有问题”,而是需要:
- 搜索代码
- 修改实现
- 运行测试
- 查看报错
- 根据结果继续修正
这就要求 harness 提供 bash 和 代码执行环境。有了这层能力,agent 才能真正运行命令、执行脚本、安装依赖、调用程序,而不是只在文本层面模拟这些行为。
这点很重要,因为许多开放任务并不适合事先封装成固定工具。与其为每个动作都单独做一个 tool,不如给 agent 一个更通用的执行入口。bash 和代码执行环境,本质上就是一种通用问题求解接口。
5. 安全执行与默认工具链:Sandboxed Environments + Tooling
让 agent 能执行,并不意味着可以让它在无边界的环境里自由行动。一旦 agent 能读写文件、运行命令、访问网络,风险也会随之增加。
因此,harness engineering 还必须处理“在哪执行”和“能执行到什么程度”的问题。这就需要:
- sandbox:把 agent 放进受控环境中,限制它能访问的资源和可执行的操作
- 权限控制:明确它可以读哪些文件、改哪些内容、使用哪些工具
- 默认工具链:预先准备好常见运行时和基础工具,例如 shell、git、测试工具、浏览器等
这样做的目的,不只是为了安全,也是为了稳定。一个合适的 sandbox 能让 agent 在一致的环境中工作,避免因为系统差异、权限混乱或依赖缺失而频繁失败。
所以,harness engineering 不是单纯地扩展 agent 的能力,而是在能力和约束之间找到平衡:既让它能做事,也让它在可控范围内做事。
6. 持久记忆与外部信息接入:Memory + Search + Connectors
模型并不会天然记住跨轮次的长期信息,也不能自动获取训练之后才出现的新知识。但现实任务往往既要求 agent 记得住上下文,也要求它查得到新信息。
因此,harness 需要提供两类补充能力:
一类是 持久记忆能力。它负责把长期有效的信息沉淀下来,例如:
- 项目的约定
- 用户偏好
- 历史决策
- 已验证过的经验
- 当前任务的中间状态
这些信息可以保存在 memory files、结构化存储或其他外部记忆机制中,在后续会话里继续复用。
另一类是 外部信息接入能力。它负责帮助 agent 访问外部世界,获取模型参数中没有的新信息,比如最新文档、实时数据、第三方系统状态,或者公司内部工具和服务中的内容。web search、mcp 以及其他 connectors,都属于这类能力的不同实现形式。
这意味着,agent 不再只能依赖“训练时知道的东西”,而是能在任务过程中不断补充和更新自己的知识基础。
7. 在长上下文中维持性能:Compaction + Tool Offloading + Skills
上下文并不是越长越好。任务一旦变复杂,历史对话、工具输出、日志信息、计划草稿会快速堆积,结果就是:
- 重要信息被淹没
- 模型注意力被分散
- 重复尝试变多
- 约束条件逐渐丢失
- 整体表现开始退化
因此,harness engineering 还要解决一个很实际的问题:如何避免上下文在长任务中逐渐失真和失焦。这里说的“上下文腐化”,指的是随着历史信息和工具输出不断堆积,关键信息被淹没、约束被冲淡、模型注意力被错误分配,导致整体表现持续退化。
常见做法包括:
- compaction:在上下文过长时压缩历史信息,保留关键状态
- tool offloading:把冗长工具输出转移到文件系统,而不是一直塞在上下文里
- skills:将复杂能力模块化,只在需要的时候按需暴露,而不是一开始全部堆给模型
这里的核心思想是:不是把所有信息都放进模型,而是让模型在需要的时候拿到最相关的信息。
这也是 harness engineering 和普通“工具拼装”的区别之一。区别不在于有没有接工具,而在于是否围绕“可靠完成任务”去系统地设计上下文管理、能力暴露、权限边界、失败恢复和验证闭环。换句话说,它关心的不是工具数量,而是这些工具能否共同构成一个可验证、可恢复、可约束的任务执行系统。
8. 完成长周期任务:Agent Loops + Planning + Verification
很多真正有价值的任务都不是一步完成的,而是需要多轮迭代、跨多个阶段持续推进。比如调试一个复杂 bug、完成一次代码迁移、做一轮市场研究,往往都需要:
- 先制定计划
- 分阶段执行
- 在中间检查结果
- 根据反馈调整路径
- 必要时重试或回退
- 最终收敛到可交付结果
这就要求 harness 具备支持长周期任务的能力。常见组成包括:
- agent loops:让 agent 不只是回答一次,而是持续执行“观察—行动—再观察”的循环
- planning:帮助 agent 把复杂任务拆成可执行步骤
- verification:通过测试、日志、截图、结果检查等方式验证是否真的完成了目标
其中,verification 尤其重要。因为 agent 最危险的地方,不是不会做,而是“以为自己做对了”。只有把验证环节纳入 harness,agent 才能从“生成一个看起来合理的答案”,走向“通过外部反馈确认结果是否正确”。